
티스토리 뷰
탐색적 데이터 분석 (EDA : Exploratory Data Analysis) 이란, 데이터를 본격 분석하기 전에 데이터의 대략적인 특성을 파악하고 의미 있는 관계를 찾아내기 위해 다각도로 접근 하는 것을 의미 합니다.
데이터 분석 시 자주 사용하는 함수
- head / tail
- 시작 또는 마지막 6개 record 만 조회
- head(,) 숫자를 넣어주면 원하는 개수만큼 확인 가능
- summary
- 수치형 변수 : 최댓값, 최솟값, 평균, 1사분위수, 2사분위수(중앙값), 3사분위수
- 명목형 변수 : 명목값, 데이터 개수
명목형 변수란 ?
그 자체로는 순서나 크기에 의미가 없는 범주, 예를 들어 성별(남성, 여성), 혈액형(A, B, AB, O) 등
표본 추출 방법
- 단순 랜덤 추출법
- N개의 원소로 구성된 모집단에서 n 개의 표본을 추출할 때 각 원소에 1,2,3, ... N 까지의 번호를 부여한다. 여기서 n 개의 번호를 임의로 선택해 그 번호에 해당하는 원소를 표본으로 추출한다.
- 예시 ) 사다리 타기, 제비 뽑기
- 계통 추출법 (systematic sampling)
- 모집단의 모든 우너소들에게 1,2,3, N 의 일련번홀르 부여 하고 이를 순서대로 나열한 후에 K 개 (K = N/n) 식 n 개의 구간으로 나눈다. 첫 구간(1,2, 3, ...K ) 에서 하나를 임의로 선택한 후에 K 개씩 띄어서 표본을 추출한다.
- 집락(군집) 추출법 (Cluster sampling)
- 모집단이 몇 개의 집락 이 결합된 형태로 구성돼 있고, 각 집단에서 원소들에게 일련 번호를 부여 할 수 있는 경우에 이용된다. 집략끼리 동질적인 부분이 있으므로 일부 집락을 랜덤으로 선택하고 선택된 각 집락에서 표본을 임의로 선택한다.
- 층화 추출법
- 상당히 이질적인 원소들로 구성된 모집단에서 각 계층을 고루 대표할 수 있도록 표본을 추출하는 방법이다. 이질적인 모집단의 원소들을 서로 유사한 것끼리 몇 개의 층 으로 나눈 후, 각 층에서 표본을랜덤하게 추출한다.
- 비례 층화 추출법과 불비례 층화 추출법
| 비례 층화 추출법 | 전체 데이터의 분포를 반영하여 각 집락별 데이터를 추출 하는 방법이다 예를들어 A 집단 200명, B 집단 300명, C 집단 500명인 표본을 추출한다면 각 집락별로 추출되는 데이터의 개수는 전체 데이터 분포의 비율과 동일하게 A:B:C = 2:3:5 를 유지하여 표본을 추출하는 방법이다 |
| 불비례 층화 추출법 | 전체 데이터의 분포를 반영하지 않고 각 집락에서 원하는 개수의 데이터를 추출하는 방법으로, 원하는 집락에서 원하는 표본의 개수를 출력한다. |
측정 방법
- 질적척도 : 범주형 자료, 숫자 크기 차이가 계산되지 않는 척도
| 구분 | 특징 | 예시 |
| 명목척도 | 측정 대상이 어느 집단에 속하는지 분류할 때 사용 되는 척도 | 성별, 출생지, 대학교 등 |
| 순서척도(서열척도) | 측정 대상의 특성이 가지는 서열 관계를 관측하는 척도 | 선호도(아주 좋아한다. 좋아한다. 그저 그렇다. 싫어한다) 신용도, 학년, 순위 등 |
- 양적 척도 : 수치형 자료, 숫자 크기 차이를 계산할 수 있는 척도
| 구분 | 특징 | 예시 |
| 구간척도 (등간척도) | 측정 대상이 갖고 있는 속성의 양을 측정하는 것 두 구간 사이의 간격이 의미가 있는 자료 절대적 크기는 측정할 수 없기 때문에 사칙연산 중 더하기와 빼기는 가능하지만 비율처럼 곱하거나 나누는 것은 불가능 | 온도, 지수 등 |
| 비율척도 | 절대적 기준인 0값이 존재하고 모든 사칙연산이 가능하며 제일 많은 정볼르 가지고 있는 척도 | 무게, 나이 ,연간 소득, 시간, 거리, 제품 가격 등 |
데이터의 척도에 따라 분석 방법을 달리 하기 위함
기술 통계와 추리 통계
- 기술 통계
- 얻어진 데이터에서 특징을 뽑아내기 위한 기술
- 수집된 자료를 정리, 요약 하기 위해 사용되는 기초적인 통계
- 평균, 표준편차, 중위수, 최빈값, % 와 같이 숫자로 표현하는 방식과 막대그래프, 원그래프, 꺾은선 그래프 같이 그림으로 표현하는 방식
- 기술 통계를 위한 통계량은 최솟값, 최댓값, 평균, 표준편차, 분산, 중앙값, 사분위수범위, 왜도, 첨도 등이 있다.
- 추리 통계 / 통계적 추론
- 통계학과 확률이론의 혼합으로 전체를 파악 할 수 없는 큰 대상이나 미래의 일에 대해 추측하는 것 (부분으로 -> 전체를 추측한다)
- 수집된 자료를 이용해 대상 집단(모집단)에 대해 의사결정을 하는 것
- 모수 추정 : 표본에서 얻은 통계치를 바탕으로 오차를 고려하여 모수를 확률적으로 추정하는 통계 기법
- 가설 검증 : 모집단의 특성을 추정하는 데 초점을 두고 가설을 검증하거나 확률적인 가능성을 파악
확률 변수와 확률 분포
- 확률변수 : 어떤 확률 실험이나 상황에서 발생할 수 있는 각각의 결과를 수치적 값으로 표현하는 변수를 의미한다. 수학적으로 표현하면, 확률변수는 정의역 이 표본공간이고 치역이 실수값인 함수다. 확률변수에는 이산형 확률 변수 와 연속형 확률변수 가 있다. 다시 말해 확률 변수에는 표본 공간에 있는 모든 원소들을 수치적 값(실수)으로 만드는 함수이다.
- 예시 ) 동전
3개의 동전을 던진다고 가정 하면 표본 공간은 어떻게 될까?
표본 공간 = {앞앞앞, 앞앞뒤, 앞뒤앞, 뒤앞앞, 앞뒤뒤, 뒤앞앞 등등등}
앞면이 나오는 개수를 Y 라고 한면, Y 가 가질수 있는 수치적 값은 ?
0, 1, 2, 3 = Y 가 바로 확률 변수 - 확률분포 : 확률변수가 특정 값들을 가질 확률을 나타내는 함수 또는 규칙을 의미한다. 즉 확률변수의 모든 값과 그에 대응 하는 확률이 어떻게 분포하고 있는지가 확률 분포이다
즉, 확률이 만들어지는 '확률 함수' 가 그리는 패턴이 확률분포 이다.
이산확률분포
이산형 확률 변수란, 사건의 확률이 그 사건들이 속한 점들의 확률의 합으로 표현할 수 있는 확률 변수를 말한다.
따라서 0이 아닌 확률값을 갖는 확률 변수를 셀 수 있는 경우를 말한다.
확률 변수가 표현하는 값이 이산형인 것
- 베르누이 분포
- 두 가지 가능한 결과 중 하나가 어떤 확률로 일어날지를 나타내는 간단한 확률 분포
- 확률 변수가 0 또는 1 두개의 결과만 갖는 분포 (베르누이 확률 함수로부터 생성된 패턴)
예시) 동전 던지기에서 앞면이 나올 확률, 시험에서 합격할 확률 등 - 이항 분포
n 번의 베르누이 시행(성공 또는 실패) 에서 K 번 성공할 확률의 분포
예시) 동전 3번 던져서 앞면이 2번 나올 확률, 3번의 제비뽑기에서 1번 당첨될 확률 등 - 기하 분포
성공 확률이 p인 베르누이 시행에서 첫 번째 성공이 있기까지 K 번 실패할 확률
예시 ) 동전을 던져서 3번째에 앞면이 나올 확률 - 다항 분포
- 이항 분포를 확장한 개념으로 n 번의 시행에서 각 시행이 3개 이상의 결과를 가질 수 있는 확률 분포 - 포아송 분포
- 시간과 공간 내에서 발생하는 사건의 발생 횟수에 대한 확률 분포
- 예시) 교재에 오타가 5페이지 당 10개씩 나온다고 할 경우 한 페이지에 오타가 3개 나올 확률
정해진 시간 안에 어떤 사건이 일어날 횟수에 대한 기댓값
연속확률분포
연속확률분포란, 가능한 값이 실수의 어느 특정구간 전체에 해당하는 확률변수를 의미한다. (확률밀도함수)
확률 변수가 표현하는 값이 연속형 인것
연속확률 변수의 예시 : 신생아의 몸무게, 태풍으로 내린 강우량, 시간 등
균일 분포
- 모든 확률 변수 X 가 균일한 확률을 가지는 확률 분포
-예시) 얼마나 들어 있는지 알 수 없는 150ml 음료수 안에 들어 있는 음료수의 양 등
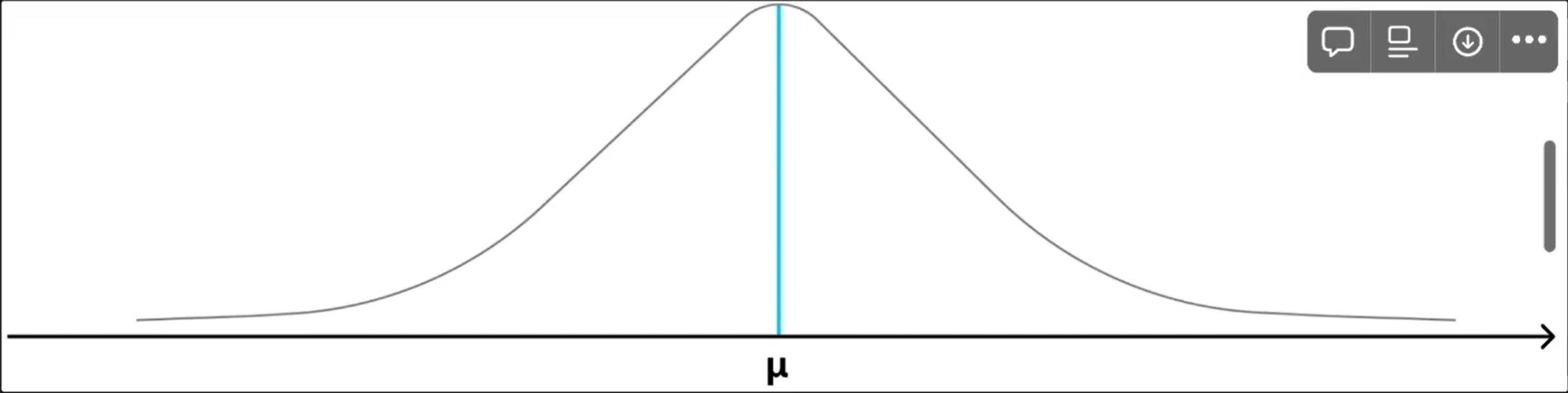
정규 분포
- 평균이 U 이고, 표준편차가 시그마 인 분포
- 표준 편차가 클 경우 퍼져보이는 그래프가 나타난다
- 예시 ) A 고등학교의 3학년 수학 점수의 분포 등
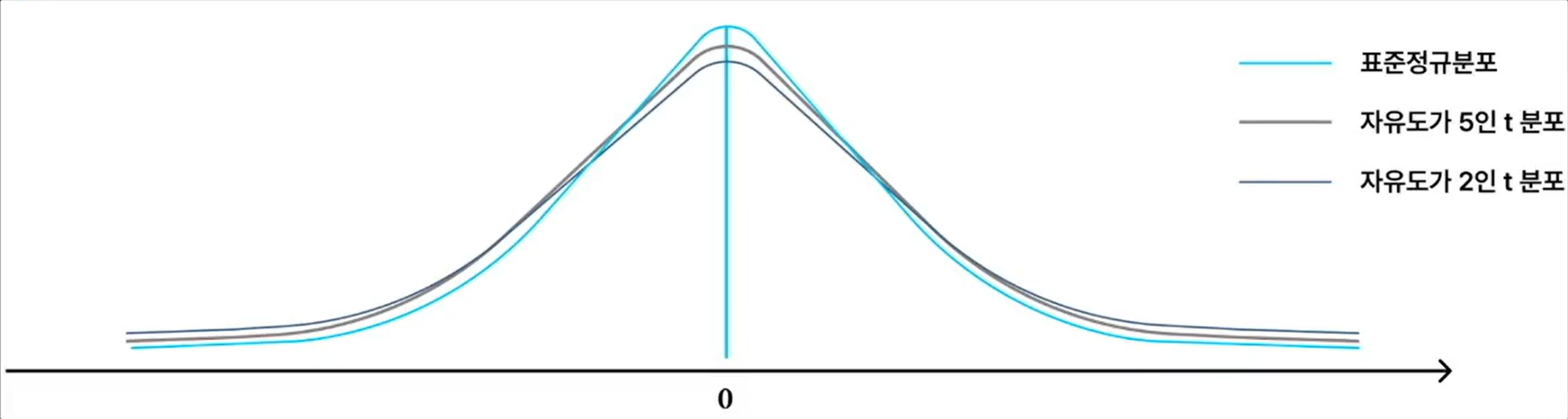
- t- 분포 ( t-Distributuin)
- 통계적으로 표본으로부터 모집단의 평균에 대한 추정을 할 때 사용되는 분포
- 표준정규분포와 같이 평균이 0을 중심으로 좌우가 동일한 분포를 따른다
- 정규분포와 유사하지만 적은 표본으로부터 얻은 통계량의 분포를 더 정확하게 나타낸다.
- 두 집단의 평균이 동일한지 알고자 할 때 검정통계량으로 활용된다.
- 표본의 크기가 적을 때는 표준정규분포를 위에서 눌러놓은 것과 같은 형태를 보이지만 표본이 커져서 자유도가 증가하면 표준정규분포와 거의 같은 분포가 된다.
*자유도란 ?
표본자료들이 모집단에 대한 정보를 주는 독립적인 자료의 개수를 의미한다. 예를 들어 사탕 4개와 사람 4명이 있을 때 앞의 3명까지는 원하는 사탕을 선택 할 수 있다. 하지만 마지막 사람은 선택권이 없기 때문에 남은 사탕을 가져갈 수 밖에 없다. 따라서 자유도는 4명에서 하나 적은 3이 된다.
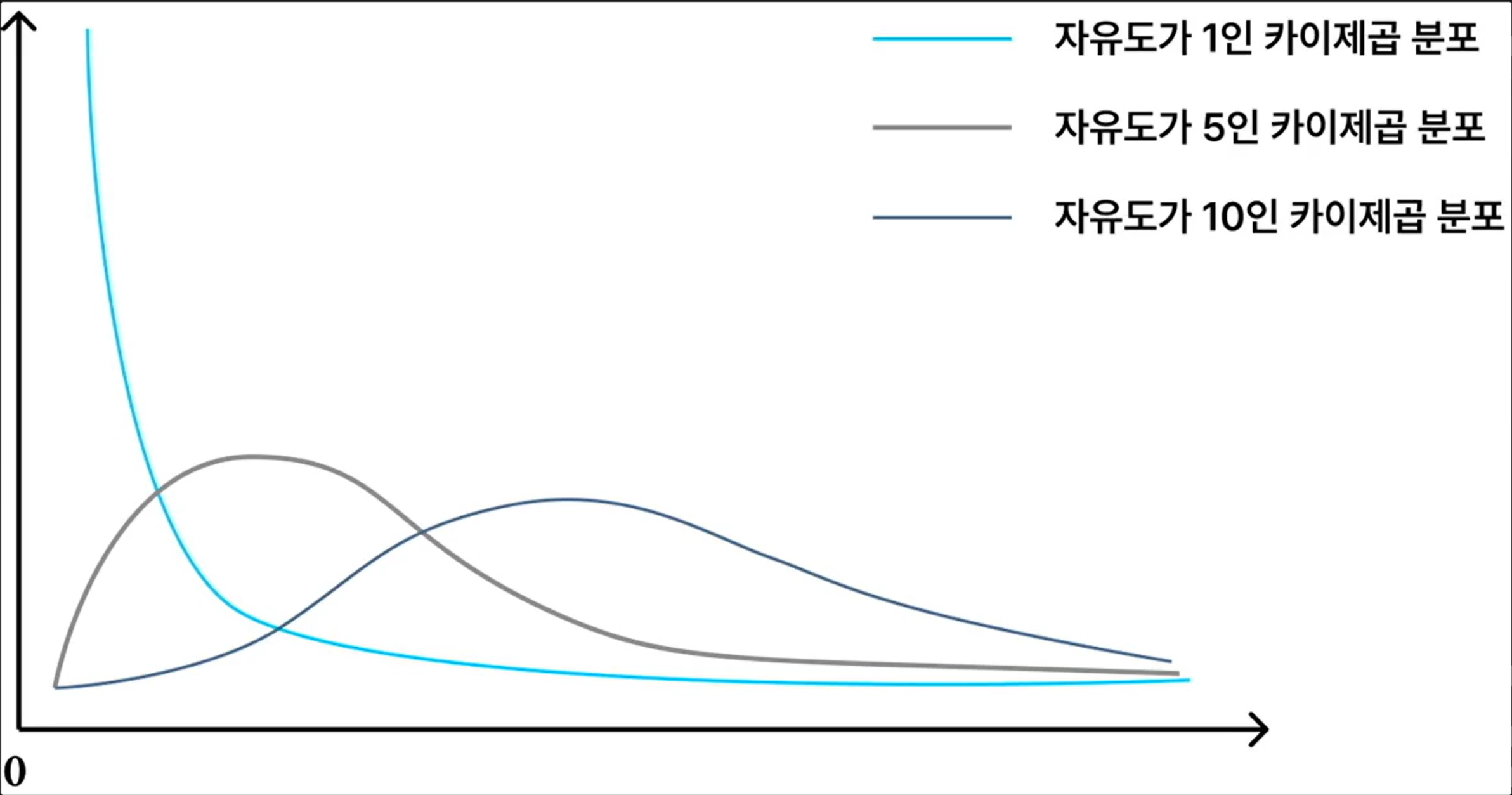
카이제곱 분포 (CHi-Square Distibution)
- 표준정규분포를 따르는 확률변수들의 제곱을 합한 분포
- 모평균과 모분산을 알려지지 않은 두 개 이상의 집단 간 동질성 검정 또는 모분산 검정을 위해 활용
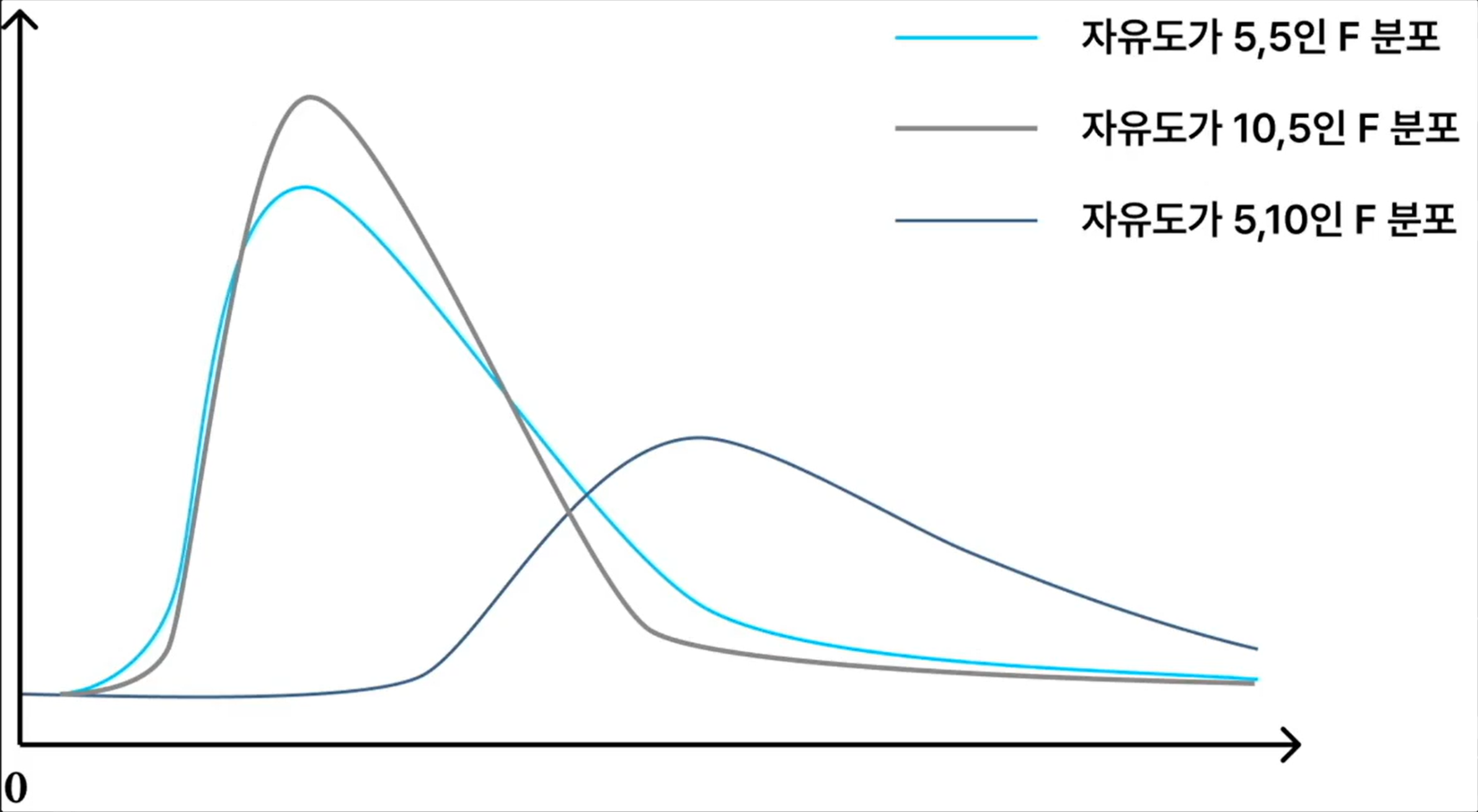
F 분포 (F-Distribution)
- 두 집단 간 분산의 동일성 검정에 사용되는 검정 통계량의 분포
- 확률변수는 항상 양의 값만을 갖고, x2 분포와 달리 자유도를 2개 가지고 있으며 자유도가 커질수록 정규 분포에 가까워 진다.
추정과 가설검정
통계에서 매우 중요한 개념인 추정과 가설검증 학습하기
- 추정
- 통계적 방법론을 통해서 알고자하는 대상은 모집단의 확률분포이다. 모집단의 확률분포의 특징을 표현하는 값들은 모수 라고 한다.
- 모수의 예) 모집단의 평균, 분산, 표준편차, 백분위수 등
- 현실적으로 모집단 전체를 대상으로 조사하는 것은 거의 불가능하거나 쉬운 일이 아니기 때문에 대부분 표본조사를 실시하여 모수를 추정한다.
- 통계적 추론은 추정과 가설검증으로 나뉘고, 추정은 점추정과 구간추정으로 나뉜다. - 점추정 (Point Estimation)
- 가장 참값이라고 여겨지는 하나의 모수의 값을 택하는 것
- 즉, '모수가 특정한 값일 것' 이라고 추정하는 것
- 모평균을 추정하기 위한 추정량(estimator)은 표본집단의 표본평균 이 대표적이다. - 구간추정 (Interval Estimation)
- 점추정은 '모수가 특정한 값을 것' 이라 예상하는 반면, 구간추정은 일정한 크기의 신뢰수준 (confidence level) 으로 모수가 특정한 구간에 있을 것이라고 선언하는 것이다.
- 항상 추정량의 분포에 대한 전제가 주어져야 하고, 구해진 구간 안에 모수가 있을 가능성의 크기(신뢰 수준) 가 주어져야 한다.
- 신뢰도(신뢰수준)로는 90%, 95% , 99% 의 확률을 이용하는 경우가 많다.
- 95% 신뢰수준 하에서 모평균의 신뢰구간
- 모분산 a2 이 알려져 있는 경우

가설검증
- 가설검정 개념
- 가설 검정이란 모집단에 대한 어떤 가설을 설정한 뒤에 표본관찰을 통해 그 가설의 채택여부를 결정하는 분석 방법이다.
- 표본 관찰 또는 실험을 통해 귀무가설과 대립가설 중에서 하나를 선택하는 과정이다. - 귀무가설 (null hypothesis)
- '비교하는 값과 차이가 없다, 동일하다' 를 기본개념으로 하는 가설
- 흔히 Ho 로 나타낸다.
- 실험, 연구를 통해 기각하고자 하는 어떤 가설로 대립가설과 상반되는 개념이다.
- 예를 들어, 어떤 약의 효과를 검정하는 경우 귀무가설은 "이 약의 효과가 없다" 라는 주장일 수 있다.
검정을 통해 귀무가설을 기각한다면, 이는 해당 약이 효과가 있다는 강력한 증거로 해석될 수 있다. - 대립가설 ( alternative hypothesis)
- 뚜렷한 증거가 있을 때 주장하는 가설
- 귀무가설이 틀렸다고 판단될 경우 채택되는 가설로 H1 로 나타낸다.
- 실험, 연구를 통해 증명하고자 하는 새로운 아이디어 혹은 가설에 해당한다. - 제 1종 오류와 제 2종 오류
- 제 1종 오류 : 귀무가설 이 사실인데, 귀무가설을 기각하는 오류
- 제 2종 오류 : 귀무가설이 사실이 아닌데도, 귀무가설을 채택하는 오류

- 검정 통계량 (test statistic)
- 귀무가설의 채택 여부를 판단하기 위해 표본조사를 실시하고, 관찰된 표본으로부터 얻을 수 있는 값
- 귀무가설의 옳고 그름을 판단할 수 있는 값 - 기각역 (Critical Region)
- 간단하게 말하면, 기각역은 표본 데이터가 특정 범위에 속할 때 귀무가설을 기각하는 영역을 의미한다.
- 기각역은 귀무가설을 기각하게 될 검정통계량의 영역으로, 검정통계량이 기각역 내에 있으면 귀무가설을 기각한다.
- 반대로 검정통계량이 기각역 밖의 채택역 에 있으면 귀무가설을 기각할 수 없다. 기각역의 경곗값을 임곗값 이라고 한다.
- 기각역은 C 로 나타낸다. - 유의 수준 (significance level)
- 귀무가설을 기각하게 되는 확률의 크기로 '귀무가설이 옳은데도 이를 기각하는 확률의 크기 (최대 허용한계)'
- 1%(0.01) 와 5%(0.05) 를 주로 사용하며 가설검정을 수행하는 환경에 맞게 조절할 수 있다.
- 제 1종 오류와 제 2종 오류는 서로 반비례 관계로 하나를 낮추면 다른 하나가 커지기 때문에 제 1종 오류를 허용 할 수 있는 최대 확률 유의수준(a) 을 설정하여 가설 검정을 수행한다. - 유의 확률
- 유의학률 또는 p-value 는 주어진 통계량이 귀무가설을 지지하는 정도를 나타내는 값이다.
- 귀무가설이 참이라고 가정할 때 주어진 데이터보다 더 극단적인 결과를 얻을 확률이다.
- p-value 가 유의수준 a 보다 작은 경우, 귀무가설이 참이라고 가정했을 때 이러한 결과가 나올 확률이 매우 적다고 볼수 있다.
비모수검정
- 통계적 추론에서 모집단의 모수에 대한 검정에는 모수적 방법과 비모수적 방법이 있다.
- 모수적 검정방법
- 검정하고자 하는 모집단의 분포에 대한 가정을 하고, 그 가정 하에서 검정통계량과 점정통계량의 분포를 유도해 검정을 실시하는 방법
- 관측된 자료를 이용해 구한 표본평균, 표본분산 등을 이용해 검정을 실시한다. - 비 모수적 검정방법
- 자료가 추출된 모집단의 분포에 대해 아무 제약을 가하지 않고 검정을 실시하는 검정방법으로, 관측된 자료가 특정 분포를 따른다고 가정할 수 없는 경우에 이용된다.
- 관측된 자료의 수가 많지 않거나 (30개 미만) 자료가 개체 간의 서열관계를 나타내는 경우에 이용한다.
- 관측값의 절대적인 크기에 의존하지 않는 관측값들의 순위(Rank) 나 두 관측값 차이의 부호 등을 이용해 검정한다.

'IT > ADsP 자격증' 카테고리의 다른 글
| ADSP 시계열 분석 및 시계열 모형 (0) | 2024.02.22 |
|---|---|
| ADsP 기술 통계 및 T 검정 (0) | 2024.02.21 |
| ADsP 자격증 코스 분석 마스터 플랜 (0) | 2024.02.20 |
| ADsP 3주차 데이터 분석 기획 (0) | 2024.02.20 |
| ADsP 자격증 코스 2주차 (1) | 2024.02.20 |
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 데이터 분석가
- 퍼포먼스 마케팅
- 아하 모먼트
- PM
- 알고리즘
- 설레다
- 프로젝트 매니저
- 머신러닝
- 데이터 분석
- 프로덕트 매니저
- 책 추천
- 아무일 없는것처럼
- 퍼포먼스 마케터
- 북극성 지표
- 빅테크
- 프로덕트 분석가
- ADsP
- 데이터 리터러시
- 기획자
- 통계학
- 데이터 분석가 주니어
- A/B테스트
- BA
- 데이터 분석 주니어
- 데이터 시각화
- 그로스 해킹
- 데이터분석가
- 빅데이터
- BI
- 방법론
- Total
- Today
- Yesterday